

The post below is an update on a research project sponsored by the eBPF Foundation. It is the second in a series of posts about this research (you can read the first here and the third here). The post was prepared by Zhe Wang (Institute of Computing Technology, Chinese Academy of Sciences; wangzhe12@ict.ac.cn), and Patrick Peihua Zhang (WeChat, Tencent; patrickzhang2333@gmail.com). Read about the status of all the sponsored research projects in this post.
In this blog, we will discuss our intuition of the isolated execution environment HIVE (referring to a beehive for the bees in the eBPF logo) and our hardware-backed isolation design for the BPF objects (e.g., BPF stack, maps, etc). For the kernel data structures that are shared to BPF (e.g., the context object), which are much more complicated, we will discuss the solution in the next blog. In future blogs, we will also discuss the corresponding solution that is pure software-based.
1. Threat Model
Building on the idea of combining verification and isolation from the previous blog, the goal of HIVE is to provide an isolated execution environment for BPF programs, replacing the full-path analysis stage in the verifier. That means the pre-process stage and CFG check stage of the verifier remain unchanged to ensure the control flow safety. We assume the pruned verifier and other components of the eBPF subsystem are secure and trustworthy.
The goal of the adversary is to compromise the security goals listed in the previous blog (Table 1) through adversary-controlled BPF programs. BPF programs may execute arbitrary legal instructions, access arbitrary memory, and call arbitrary helpers with the corresponding program type. Note that the pruned verifier still guarantees the forward control flow safety.
2. Intuition
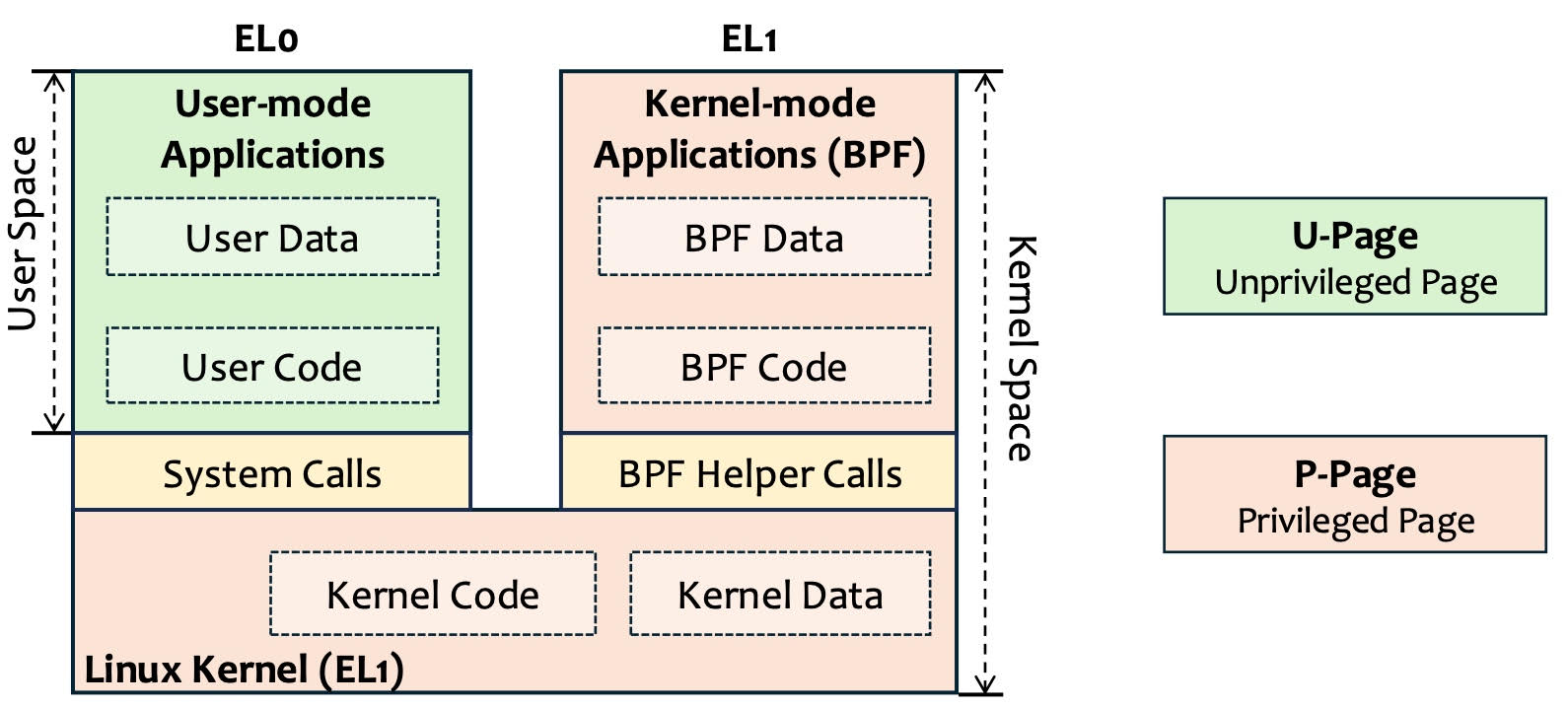
Fig. 1: User-mode Application and BPF Program Comparison
Corresponding to user-mode applications, BPF programs can be regarded as kernel-mode applications. As shown in Fig. 1, they request kernel services through system calls and helper function calls, respectively. Like BPF programs, user applications also need to be isolated to ensure the kernel’s security. And they adopt a hardware-based dynamic checking method rather than a pure software verification method:
- Exception-level-based (EL-based) memory isolation. User applications cannot access kernel memory because the kernel memory pages are all set up as privileged pages (P-Pages), which cannot be accessed by user application code running at EL0.
- Independent memory and address space. Each user application has its own independent and continuous address space, and its memory is completely decoupled from the kernel and other applications.
- Crashes are catchable and recoverable. Due to the independence of the execution state, user programs can be crash-isolated from the kernel. The kernel captures and recovers crashes via hardware exceptions.
If an isolated execution environment can be created for BPF programs, some of the heavy-lifting tasks performed by static verification can be replaced by hardware-assisted dynamic isolation. This is the key idea behind HIVE.
A naïve design is to run BPF programs in user mode just like user applications. However, it will incur very high performance overhead due to the frequent helper function calls that need to be transformed into expensive system calls. To address this problem, we choose to only de-privilege memory accesses instead of changing the privilege level of BPF programs. Our next step is to identify hardware features that can de-privilege BPF programs.
3. Unprivileged load/store on Arm
The access right of a memory access instruction is determined by the current exception level and the target memory’s permission. The code running at EL0 (i.e., user mode) can access unprivileged pages (abbreviated as U-page) in user space. Still, it cannot access privileged pages (abbreviated as P-page) in kernel space, and we refer to this as EL-based memory isolation. But the load/store unprivileged (LSU) instructions, i.e., ldtr and sttr, are an exception. No matter which EL they are executed at, they are treated as if at EL0 and thus cannot access P-pages.
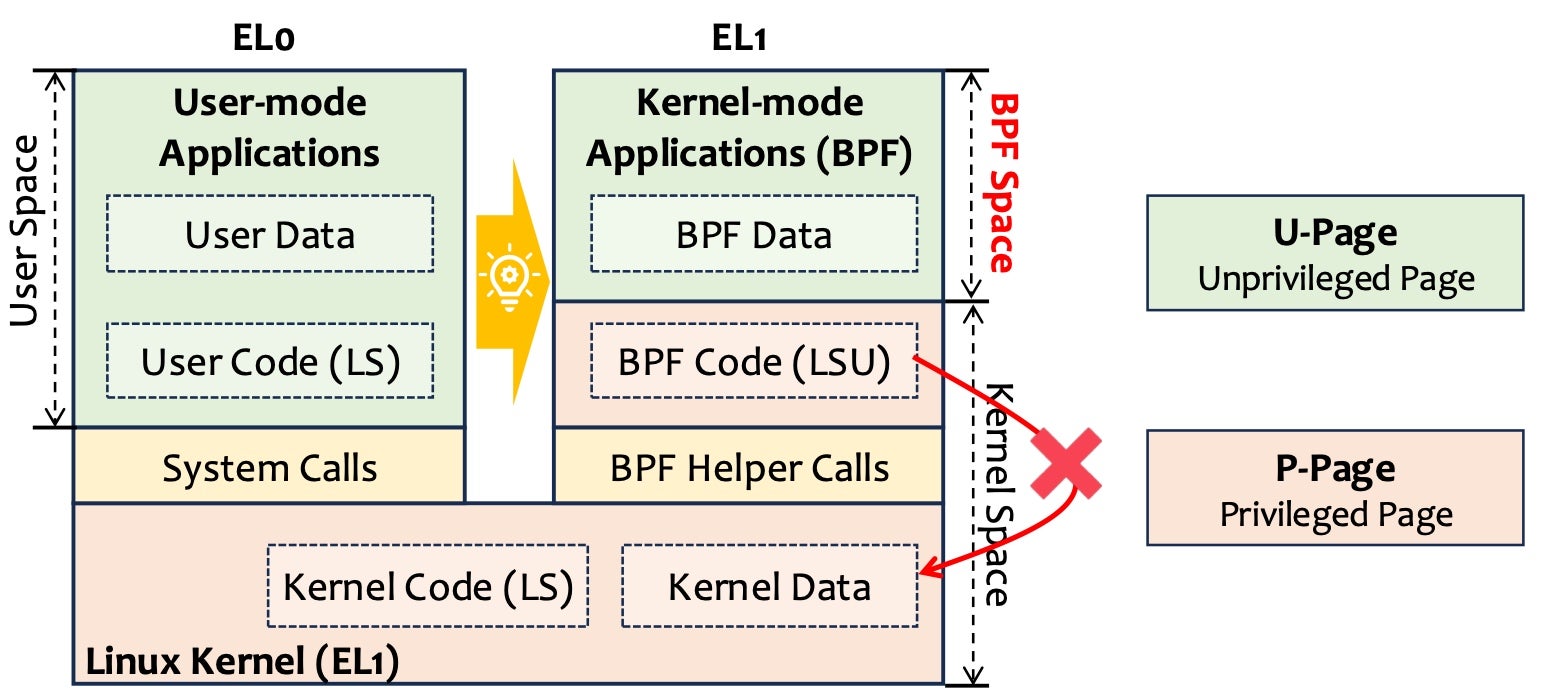
Fig. 2: De-privileged eBPF Program
As shown in Fig. 2, HIVE leverages the LSU support on AArch64 to protect the kernel memory by emitting all BPF memory access instructions as LSU instructions and setting the BPF memory to be U-Pages. Since LSU instructions use the EL0 privilege level, they can access BPF memory normally, but not kernel memory. Another advantage of this design is that BPF programs can still use helper function calls, typically without incurring high performance overhead. Note that BPF’s control flow security (i.e., it cannot use illegal instructions and arbitrarily jump to the kernel) is still guaranteed by the retained first two stages of the verifier.
Similar to user applications, each BPF program has its own independent memory and address space in HIVE, referred to as the BPF space. It is set to be U-Pages and is used solely to store BPF data. This is because the BPF code is not allowed to be modified by itself, thus it is still placed in the kernel space. There is a problem here that the BPF space is set to be U-Pages, which also prevents helper functions from accessing it legally due to the PAN (Privileged Access Never) feature. To solve this problem, HIVE double-maps a shadow BPF space of P-Page for access by helper functions. Both the shadow BPF space and the BPF space are 1TB in size and are placed at the highest address in order. In this way, BPF programs cannot infer any kernel layout information from the BPF space.
4. Object-granular Isolation
The full-path analysis tracks the type of each pointer and the range of the pointed object, ensuring that it can only access the accessible region inside the BPF data object. This is because BPF data objects are non-contiguous and interleaved with other inaccessible objects. For example, eBPF embeds object management structures (including function pointers, lock pointers, etc) into these objects, which also need protection. However, the above EL-based memory isolation cannot provide such finer-grained (or sub-page) protection.
5. BPF Memory Compartmentalization
5.1 Stack separation
BPF programs use a local stack, which is on top of the current kernel stack, to store local variables. The BPF stack frame pointer register is mapped to a physical general-purpose register (%x25 on AArch64), and all local variables are accessed through %x25 or its derived pointers. Besides, return addresses and callee-saved registers are also stored in the function frame. Still, they are only accessed through the physical stack pointer register (%sp on AArch64), which is only used by the prologue/epilogue instructions instrumented by the JIT compiler. Assume there are two functions named bar() and foo() in the BPF program. Fig. 3 shows the corresponding stack layout and one of the BPF function’s JIT code. The BPF program can only access its local variables. To separate the stack, we adopted an idea similar to the Safe Stack in LLVM — put the data that is proven to be safe (i.e., return address and callee-saved register) on the original kernel stack, and isolate the unsafe data (i.e., BPF local data) on a new stack.
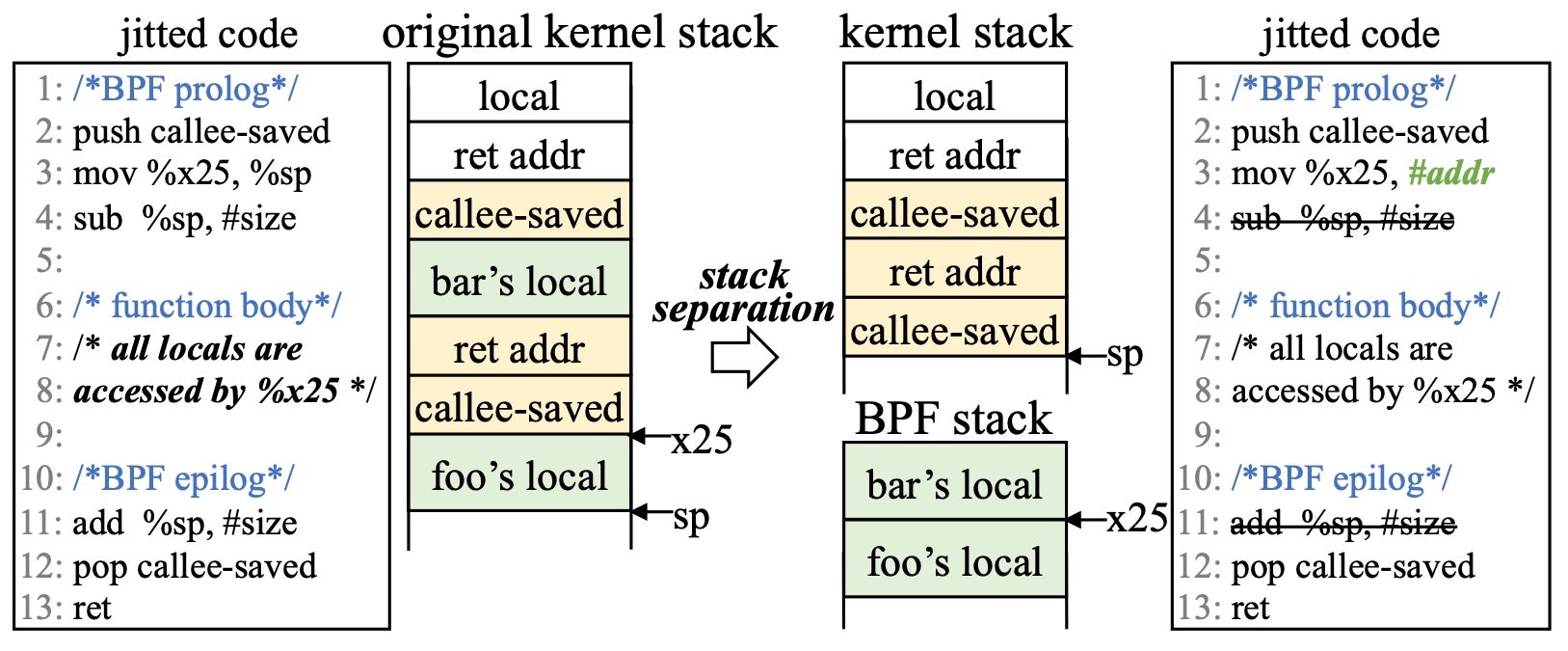
Fig. 3: Stack Separation. The kernel calls the bar() in BPF, which calls the foo() in BPF.
As shown in Fig. 3, HIVE moves the local variables into BPF space by replacing the initialization of x25 in the prologue (mov %x25, %sp) with another instruction (mov %x25, #addr), and leaving the return addresses and the callee-saved registers (which are only accessed through the sp register) on the kernel stack. The stack adjustment instructions (lines 4/11) are optimized away. HIVE instruments instructions to adjust the x25 to manage the BPF stack when entering the BPF program and calling BPF functions. Without full-path analysis, HIVE is unaware of the size of each stack frame, so it uses the upper limit (512B) allowed in eBPF as the fixed size for each frame. The size of the BPF stack is set to be 8MB by default. HIVE only allocates the bottom two pages at load time, and the remaining pages are allocated lazily via the page fault exception.
The advantage of this design is that there is no need to switch the physical stack pointer when the kernel function and the BPF function call each other. During the execution of the BPF program, the helper functions can be called directly and utilize the kernel stack. The control flow safety is guaranteed (forward control flow is ensured by the first two stages of the verifier, and backward control flow is ensured by return address isolation), instructions that operate %sp are emitted/instrumented by the JIT compiler and cannot be abused by attackers.
5.2 Maps separation
Maps are composed of metadata and values that are stored next to each other. The metadata typically contains the type, data pointers, and function pointers, which must be distinguished from the values. There are 33 distinct types of maps in the current eBPF, with mainly two types of implementations: array maps and hash maps.
The separation process is straightforward for array maps since they are stored continuously and of a fixed size. eBPF provides map properties to page-align the values, which helps HIVE to separate and only shadow the data area of the maps to the BPF space.
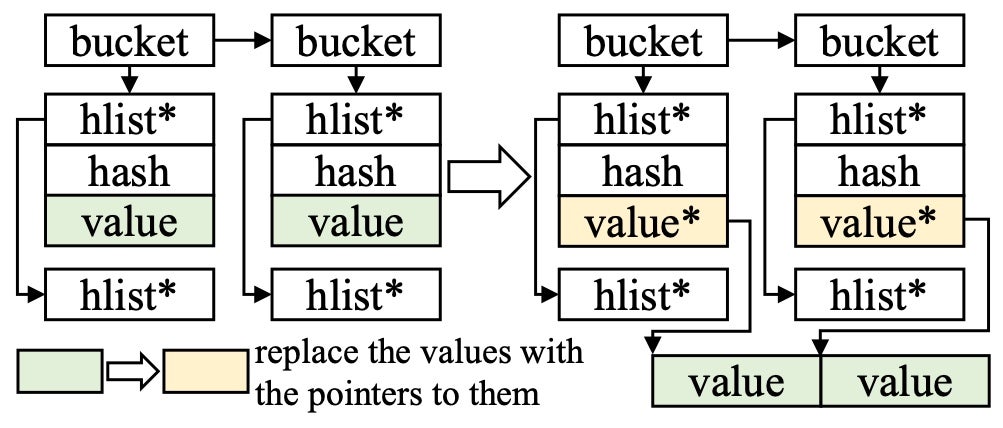
Fig. 4: The hash map separation.
However, the hash maps are stored non-contiguously, preventing HIVE from shadowing the hash maps directly into the BPF space. To this end, we slightly adjust the structure of the maps, separating all values from the maps and leaving a pointer to point to the new location of the values. Fig. 4 gives the separation of the hash_map structure; all values are separated and shadowed in the BPF space, while the metadata remains in the kernel space.
We implemented this change by adding additional logic to the helper functions, which is transparent to the BPF program because it only uses the address of the value, and parsing on the maps is handled by helper functions (or inlined helpers, which HIVE also modifies).
5.3 Packets separation
Packets, which are buffers pointed to by the data field in the context, are allocated when network packets arrive. Simply mapping them into the BPF space could bring high-performance overhead due to the packet freeing, which will cause the mapping to be canceled, which incurs the high-cost TLB shootdown. To this end, HIVE allocates the packet from a dedicated memory pool, which is implemented as a kmem_cache in the slab. It will be double-mapped into the BPF space with allowed access permissions based on the BPF program’s type, such as read-only and writable. This eliminates the need for high-cost page table manipulation.
6. BPF Memory Isolation (SG-1)
6.1 Isolation of direct memory accesses
Since HIVE separates all accessible BPF objects and maps and shadow-maps their data area in the BPF space, they no longer require object-level range checking but only need to check whether the access target is in the BPF space through the EL-based memory isolation mechanism. However, this method leads to a new problem: user programs and BPF programs can access each other’s memory.
To address this problem, HIVE leverages E0PD to enable/disable unprivileged access to user space and BPF space. Specifically, E0PD is introduced in ARMv8.5-A as a hardware mitigation to prevent the fault timing attacks launched by malicious users against the kernel. It prevents the unprivileged memory accesses to the (lower or upper or both) halves of the address space and generates a translation fault in constant time when accessing. There are two bits, E0PD0 and E0PD1, of the TCR_EL1 register that control whether unprivileged memory accesses to the lower half (user) or the upper half (kernel) of the address space are disabled, respectively.
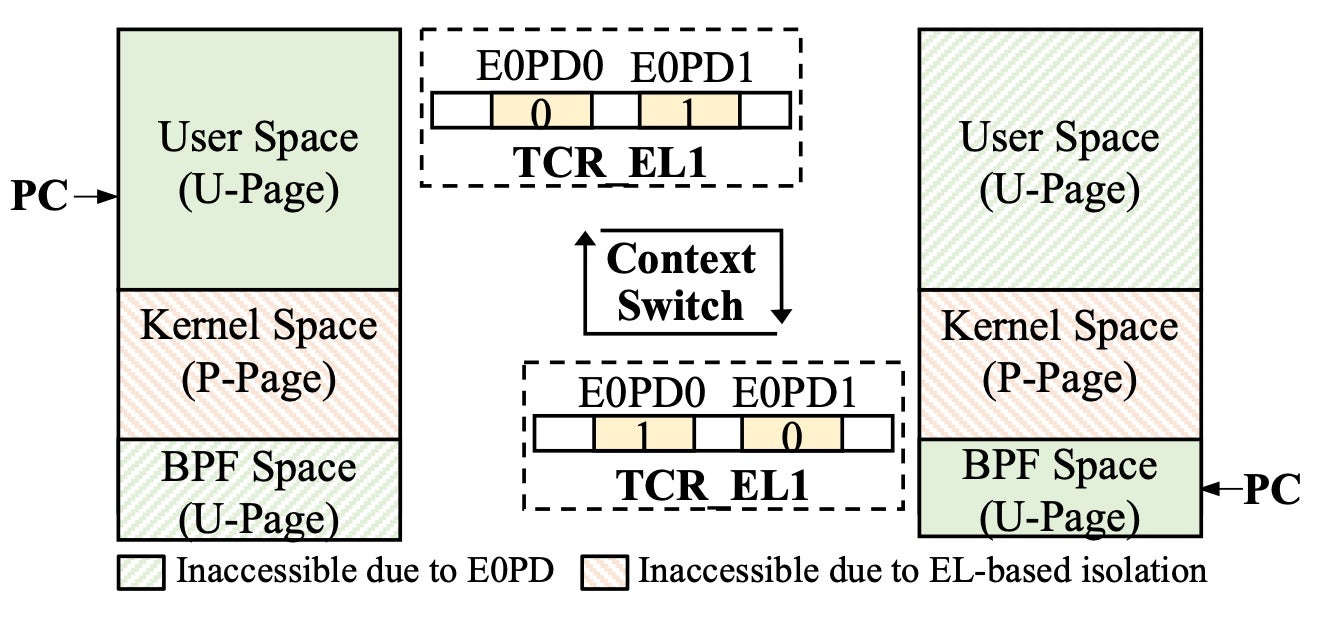
Fig. 5: The isolation between BPF, kernel, and user.
As shown in Fig. 5, when the kernel calls a BPF program, HIVE clears E0PD1 to enable access to the BPF space and sets E0PD0 to disable access to the user space. When the kernel returns to the user program, HIVE checks if any BPF program has executed; if it has, HIVE reverses the E0PD settings. This design can avoid unnecessary E0PD settings, such as a single kernel service request that does not call any BPF program.
All E0PD-related settings require only a single instruction to change the corresponding bits in the TCR_ELx register. This instruction costs 47 cycles in our evaluation, which is negligible compared to the whole context-switching.
6.2 Sanitization of helper’s parameters
These BPF object pointers can be passed to helpers through parameters. The full-path analysis performs range and type checking for the parameters that HIVE should also do. Besides, these pointers also need to be converted to point to the P-Pages when passed to helpers. This is because the helper function uses the regular load/store instruction and cannot access the BPF space of the U-Page attribute when PAN (Privileged Access Never) is enabled by default. Although temporarily disabling PAN when calling the helper function can solve this problem, it will compromise the kernel’s security. To address this, HIVE double-maps a shadow BPF space of the P-Page attribute for the BPF space and converts the pointers before passing them to helper functions.
Benefiting from the design of BPF space memory layout and alignment, as well as the range and type checking, pointer conversion can be performed through a single logical operation instruction. HIVE instruments an orr xn, 0xffffff0000000000 instruction for each function parameter of the BPF objects pointer before calling helpers. In this way, the kernel can access the BPF space in a disguised way while the pointer is also checked. Note that an attacker may set a pointer point to the boundary of the BPF space to induce helpers to access memory outside the BPF shadow space. But it is safe that the helper will overflow access to BPF space and trigger permission fault.
6.3 BPF Objects Isolation Summary
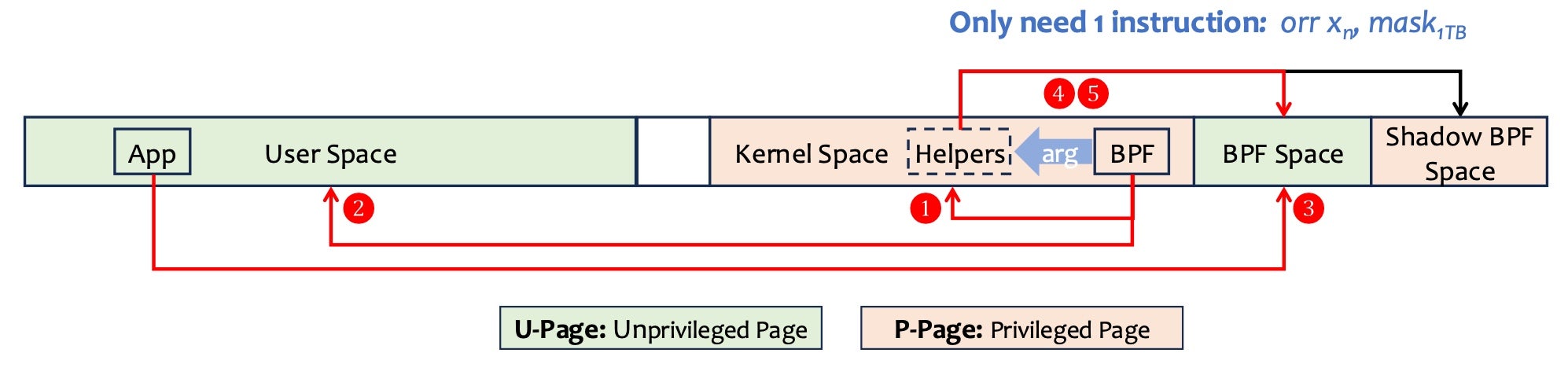
Fig. 6: Isolation for the BPF Space
As shown in Fig. 6, the BPF space isolation is ensured by the following mechanisms:
- BPF program cannot access the kernel space because LSU cannot access P-pages;
- BPF program cannot access the user space because E0PD0 forbids unprivileged access to the lower half space;
- The user program cannot access the BPF space because E0PD1 forbids unprivileged access to the higher half space;
- Helpers cannot be abused to access the kernel space because pointer parameters are masked when calling helpers;
- Helpers can access unprivileged BPF space transparently because pointers are redirected to the shadow BPF space.
7. Information Leakage Prevention (SG-2)
As discussed in the previous blog, SG-2 is separated into three categories. We discuss how HIVE ensures each security goal as follows:
- Independent address space (SG-2.1). HIVE creates an independent address space for each BPF program and ensures that separated BPF objects are randomly mapped into it. All the BPF object pointers are relocated to point to this space. Thus, attackers cannot infer any kernel layout information from these pointers that can be safely leaked.
- Use after initialization (SG-2.2). HIVE initializes all memory allocated in the BPF space at load time. Each time the BPF program is executed, the BPF stack of the current core is reused without reinitialization. If an uninitialized read of the BPF stack occurs, it will still access the content of the last execution of the same program and will not cause memory leaks in the kernel.
- Convert Spectre to Meltdown (SG-2.3). The key to Spectre v1 and v4 attacks is to transiently access sensitive data and use its value to encode and access a legitimate memory address that can cause a change in the cache state. BPF programs use LSU instructions in HIVE; thus, accessing the kernel space (speculatively) will cause a permission fault. A hardware patch named CSV3 was added to mitigate the Meltdown attack, which forbids the data loaded under speculation with a permission fault to be used to form an address to be used by other instructions in the speculative sequence. Therefore, thanks to the transformation of LSU instructions and the CSV3 patch, Spectre attacks can be blocked at the hardware level without any software effort. In a nutshell, HIVE converts Spectre problems into the Meltdown problem, which the hardware patch can prevent.
8. Summary
This blog discusses our isolated execution environment for BPF objects, which primarily consists of two steps: compartmentalization and isolation. In the next blog, we will introduce the main difference between BPF objects and the kernel objects that are shared with BPF. Based on that, a dedicated solution will be discussed.