

The post below is an update on a research project sponsored by the eBPF Foundation. It is the first in a series of posts about this research (you can read the second here). The post was prepared by Zhe Wang (Institute of Computing Technology, Chinese Academy of Sciences; wangzhe12@ict.ac.cn), and Patrick Peihua Zhang (WeChat, Tencent; patrickzhang2333@gmail.com). Read about the status of all the sponsored research projects in this post.
1. Project Overview
eBPF has evolved into a foundational technology in the Linux kernel, powering diverse subsystems from networking to observability. To safeguard kernel integrity, BPF programs undergo static verification before execution. However, the eBPF verifier faces challenges—security vulnerabilities and inherent complexity—that undermine its reliability.
In response, we propose a paradigm shift: redefining BPF programs as kernel-mode applications requiring dedicated isolation. This project introduces a novel execution environment designed to isolate BPF programs, offering an alternative architectural solution to enhance the security and scalability of eBPF infrastructure.
We systematically analyzed the eBPF verifier’s objectives to achieve equivalent security guarantees. This post serves as the first installment in our series, providing a structured summary of the verifier’s security guarantees in Linux v6.16. We focus specifically on unprivileged programs, as their requirements subsume those of privileged programs.
In subsequent blogs, we will discuss our design methodologies—including hardware-assisted and Software-Based Fault Isolation (SFI) approaches—alongside current milestones, challenges, and future directions.
2. Verifier Workflow
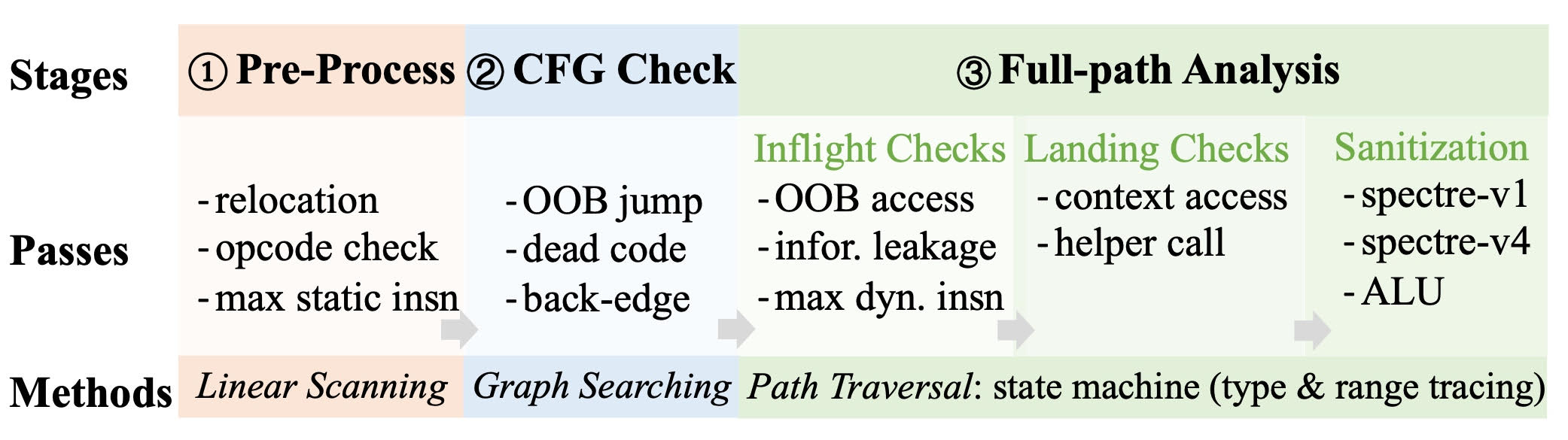
Fig. 1 The workflow of the verifier.
The workflow of the verifier consists of three consecutive stages, with the later stages becoming more complex. As shown in Fig.1, the pre-processing stage scans the BPF program linearly to find relocation items and check for any unallowed opcodes, e.g., indirect calls (calls). The CFG check stage searches the control flow graph and forbids any out-of-bounds jumps or unreachable codes, thus ensuring the control flow integrity.
The last stage creates a state machine that records the type and range of all registers and stack slots during the path exploration. Meanwhile, it verifies that all states conform to a set of security properties that do not threaten the kernel, thus, e.g., ensuring memory safety. Since it traverses all possible paths, we call it full-path analysis. The full-path analysis performs most of the analysis and integrates the majority of security checks; focusing on it allows for a comprehensive understanding of the verifier’s capabilities and limitations.
3. The Internals of Full-path Analysis
3.1 The Methodology of Study
Due to the lack of comprehensive documentation discussing the verifier, we had to understand its design manually. To this end, we undertook a top-down analysis from the verifier’s entry to all exits. We collected all checks and scrutinized the triggering conditions, the check’s content, its dependencies, and restrictions. To ensure comprehensiveness, we also performed a bottom-up analysis, beginning with all the verifier’s error messages to ensure no checks were overlooked.
All checks share a distinguishing feature: a conditional judgment statement with an error message output (e.g., verbose()). Some of these checks are not related to the full-path analysis. For example, the division-by-zero check checks if the imm operand in the instruction is 0. Filtering such checks is simple by inspecting whether the condition contains the env. This is due to the program state used in the state machine being recorded in the verifier’s environment structure (struct bpf_verifier_env *env).
Among all the checks, some are complexity or functionality checks, such as the combined branch state cannot exceed 8,192 to prevent state explosion. We filter these checks by understanding their semantics, supplemented by the error message. For example, these checks usually contained phrases like “too many” or “too complex”. Conversely, the security checks typically contained “prohibited” or “invalid”. By understanding the filtered security checks and their semantics, we obtain all the security properties the verifier wants to ensure in the full-path analysis.
3.2 The Security Properties in Full-path Analysis
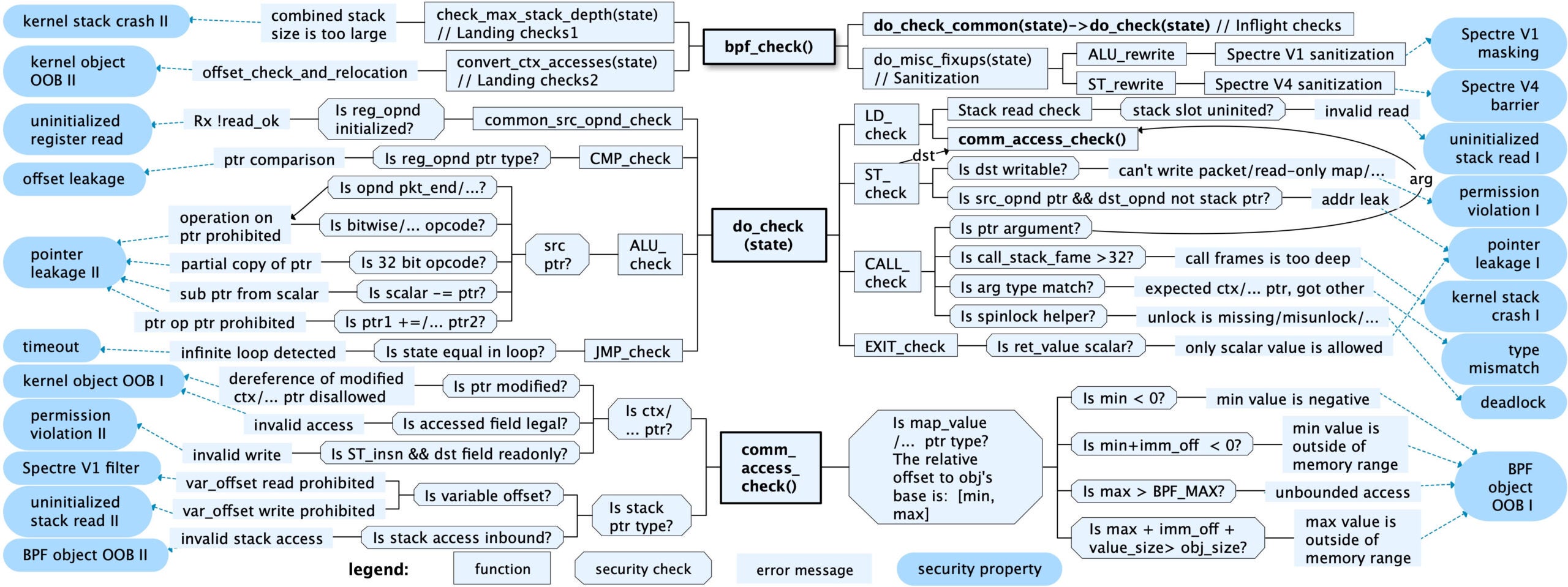
Fig. 2 The security checks and corresponding security properties in the full-path analysis.
Fig.2 gives a panoramic view of how the verifier performs the security checks in the full-path analysis. The bpf_check() function is the entry point of the verifier, and the do_check() it calls contains most of the security checks. We call them inflight checks since they are performed during the path traversal along with the state tracking. Whenever an instruction is encountered, it will perform security checks based on the semantics of the instruction and all operands’ states (i.e., the type and the value range). For example, it checks whether the pointer can be stored in the maps to prevent information leakage. It maintains a state machine and performs a circular tree-style check. Based on the type of each instruction on each possible execution path, it sets up different checks. For example, memory access instructions check if the memory access is valid based on the type of source pointer. Once it detects illegal behavior, it outputs the corresponding error message and rejects the BPF program. If the instruction passes the check, the state machine will be updated accordingly.
After the inflight check, the check_max_stack_depth() function and the convert_ctx_accesses() function are called in sequence to perform global security checks, which we call the landing checks. the landing checks and sanitization are performed based on the state machine. For instance, the inflight check records the maximum depth of every stack access of each function, and the landing checks ensure that the combined BPF stack size does not exceed the upper limit to prevent kernel stack crashes. Additionally, the inflight checks are used to calculate the mask value for instrumentation in Spectre V1 masking instructions.
The verifier contains hundreds of security checks; we have merged and simplified similar security checks in Fig.2 for ease of introduction. The left and right sides summarize these security checks’ summarized 20 security properties. We discuss them as follows:
- The verifier tracks all the BPF objects’ sizes and permissions, and the pointers’ bounds point to them, thus whenever a BPF object is accessed, it forbids underflow/overflow and permission mismatch (BPF object OOB I/II, and permission violation I).
- For BPF-accessible kernel objects, the verifier uses its whitelist, which records all readable/writable fields of each type of kernel object, ensuring legal fields with correct memory access width (kernel object OOB I/II, and permission violation II). This is because the kernel objects access instructions are verified and adjusted due to the mechanism introduced in [bpf: allow extended BPF programs access skb fields] (https://lwn.net/Articles/636647/).
- When calling a helper function, it ensures each parameter matches the formal arguments in the signature (type mismatch).
- It maintains the status of each stack slot thus pointers can be spilled into the stack and restored to the register. However, the BPF program cannot store pointers in other memory, because their later usage is not tracked, thus unable to prevent pointer leakage (pointer leakage I). Any operation that may leak the pointers indirectly (e.g., bitwise, compare) is not allowed (pointer leakage II and offset leakage).
- The stack memory and BPF registers may contain residual kernel information (e.g., pointers), it forbids operation that may lead to uninitialized access (uninit reg read, uninit reg read I/II).
- The verifier only considers Spectre V1 and V4 attacks, which are mitigated via different solutions. For example, Spectre V1 attack is mitigated by the alu_sanitizer (https://lore.kernel.org/lkml/20210505112325.000317999@linuxfoundation.org), which adds mask instructions to prevent possible OOB speculative access. It also restricts stack access to simplify the Spectre V1 analysis (Spectre V1 filter/masking). The barrier instruction mitigates Spectre V4 if a possible speculative store is detected (Spectre V4 barrier).
- The call frame of the BPF program cannot be too deep (e.g., less than 32) because it may crash the kernel stack (kernel stack crash I). Similarly, the size of the combined BPF program stack of the deepest call frame cannot be too large (kernel stack crash II).
- The kernel disables the preemption when the BPF program executes. Thus, the BPF program cannot stuck (e.g., dead loop, deadlock) to keep the kernel functional (timeout/deadlock).
While some security checks have explicit security properties that can be summarized based on judgment conditions and error messages, some properties need to be inferred. Take uninitialized stack read II as an example, BPF programs are not allowed to write to the stack using variable offsets due to the state maintenance of stack slots. When a variable offset is involved and a stack slot is uninitialized, the verifier cannot determine if this write would initialize this slot or not, potentially leading to an uninitialized stack read.
3.3 The summarized security goals
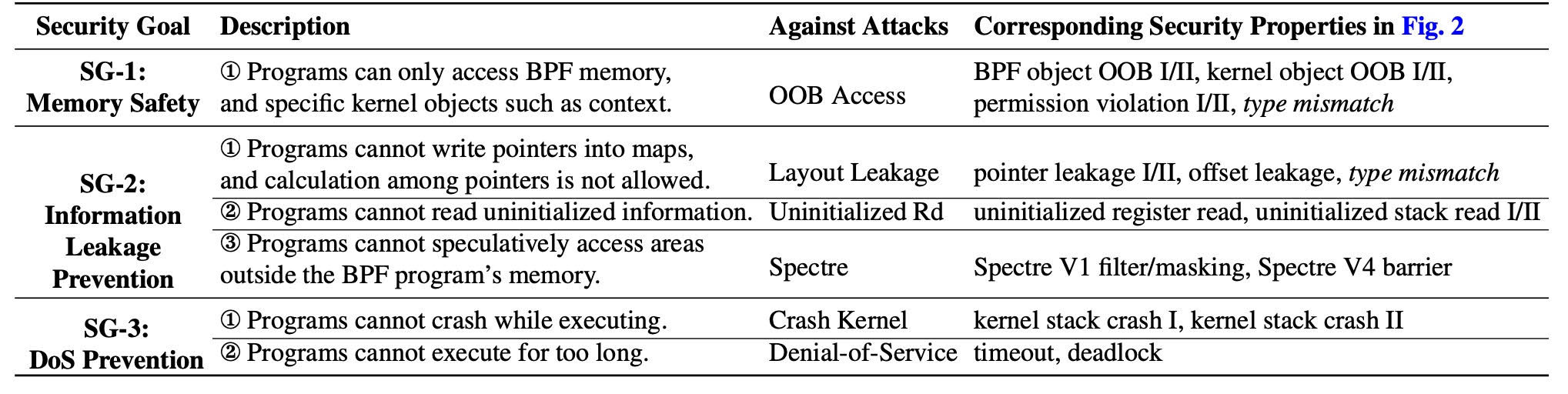
Table 1. Summarized security goals and their corresponding security properties.
Security properties are the security that the verifier must ensure at the implementation level. Based on them, we also summarize the security goals at the design level, as shown in Table 1. For SG-1, BPF programs can only access their own memory. The permission violation and type mismatch between pointers could lead to illegal memory access. Thus, they are also related to memory safety. For SG-2, the information leakage should be prevented, including kernel layout, uninitialized information, and kernel memory accessed speculatively. Besides, the type mismatch between scalars and pointers could also leak kernel layout. For SG-3, DoS attacks should be prevented because the preempt is disabled when the BPF program is running, and the exception handling is not supported in eBPF.
4. The Dilemma of Full-path Analysis
The complicated design and implementation of the full-path analysis have become a burden for the verifier. Although eBPF developers have been dedicated to improving the verifier, it still faces the following dilemmas.
4.1 The Capability Dilemma
Several restrictions are imposed on the program to avoid the state explosion problem and ensure the analysis can finish constantly, including limiting the number of loops and branches. Kernel developers have recognized this challenge and tried to address it over the years. For example, eBPF introduced function calls and supported the intra-procedure analysis instead of the whole program in 2017, allowing programmers to break down complex functions into more straightforward functions for individual analysis. However, it could lead to state overestimation and even exacerbate complexity problems. Constant loops were supported in 2019 after extensive design and attempts. Helper functions such as bpf_loop() and bpf_for_each_map_elem() were introduced in 2021 to handle unique loops. However, while these functions seemingly address the loop problem, they impose limitations on passing state between loop iterations, along with the loop body and condition, deviating from commonly used loop patterns. Even worse, the complexity Issue sometimes intensified with bpf_loop().
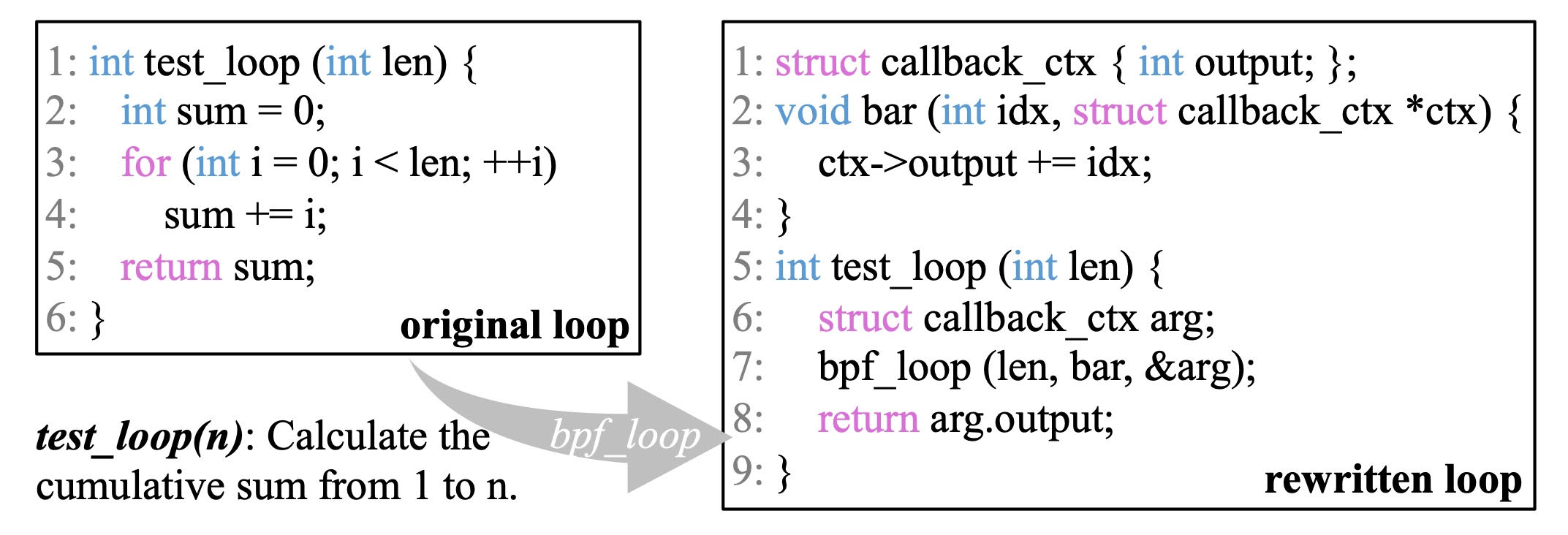
Fig.3. The code example of bpf_loop()
Fig.3 gives an example of the bpf_loop() helper; the original loop uses the i < len statement as the loop condition. Since the len variable may be unknown at the loading time, the full-path analysis has to speculate its range as large as possible (e.g., u32_max), thus failing to enumerate all program states, leading to program rejection. The bpf_loop() helper tries to solve this problem by encapsulating the loop body into a new function (bar() in the example), callback it using bpf_loop() with len as its call count and arg as its argument. The bpf_loop() will call the bar() for len times and pass the index from 0. Inside the bar(), it stores the computed result and returns 0, which means continue for the loop, while returning 1 means break the loop.

Fig. 4. The negative example of bpf_loop().
While this helper addresses the complexity issue, it could worsen the problem. As Fig. 4 shows, the original function can pass the verification but fails after being rewritten by the bpf_loop(). This is due to the inability to pass states between the loop body and condition. For example, in the original function, the i variable is always less than len (less than 16). Thus, the memory access instruction in line 6 is safe. After the loop body becomes an independent function, which is verified independently, the full-path analysis cannot ensure the range of idx, thus rejecting the BPF program for possible OOB access. Besides, this callback style function restricts pointer passing between function calls. Thus, the loop body cannot use self-defined pointers (buf in line 4), another limitation. Up to now, complex BPF programs still cannot pass the verification.
4.2 The correctness dilemma
The code size and complexity of the full-path analysis have significantly increased over the years, making formal verification challenging and leading to design and implementation bugs. The full-path analysis has been responsible for over 90% of CVEs in the eBPF verifier in the past decade. Moreover, attempts to address complexity have resulted in additional security issues, such as out-of-bound access and potential denial-of-service vulnerabilities introduced by the bpf_loop(). For example, in 2023, kernel developers found that the bpf_loop() led to additional security issues due to it only checking the loop body’s state for the first loop time, which would cause out-of-bound access. Besides, it would cause DoS because it allows nested calls to it. With the combination of eBPF tail calls, one BPF program could run for millions of years.
To the best of our knowledge, no existing work has proved the completeness and soundness of the full-path analysis. In contrast, the JIT compiler in eBPF has been verified due to its simple logic. As a result, the Linux community has dismissed unprivileged eBPF programs (enabled in 2015 as an unsafe feature that should not be used despite their great potential.
5. Summary
While verification-based methods offer distinct advantages (e.g., eliminating runtime overhead), their limitations remain non-negligible. BPF programs, as a new category of user-defined code, could adopt isolation mechanisms akin to those used in user-mode processes—another form of user-defined programs. This raises the possibility of combining verification and isolation into a hybrid security framework: verification could handle lightweight checks (e.g., opcode validation and CFG analysis, as illustrated in Stages 1 and 2 of Figure 1), while isolation mechanisms provide additional runtime safeguards.
Notably, the lifecycle of BPF programs shares similarities with JavaScript execution. Both paradigms involve bytecode-level verification before execution and runtime security checks—enforced by interpreters or instrumented JIT-compiled code. This layered approach balances static analysis with dynamic enforcement, potentially offering a robust security model for BPF without sacrificing flexibility.
Read the next post in this series at https://ebpf.foundation/research-update-isolated-execution-environment-for-ebpf-part-2/.