

The post below is an update on a research project sponsored by the eBPF Foundation. It is the third in a series of posts about this research (you can read the first here and the second here). The post was prepared by Zhe Wang (Institute of Computing Technology, Chinese Academy of Sciences; wangzhe12@ict.ac.cn), and Patrick Peihua Zhang (WeChat, Tencent; patrickzhang2333@gmail.com). Read about the status of all the sponsored research projects in this post.
Recap. In Blog 2 we showed how HIVE handles inclusive type pointers (those pointing to BPF objects) by decoupling fragmented BPF objects and isolating them in a unified BPF space protected by AArch64’s LSU instructions and E0PD. In this blog, we tackle the harder half of the problem: exclusive type pointers, which point to kernel objects that BPF programs are allowed to share with the kernel. We first explain how BPF programs access kernel objects and how the verifier secures them, then summarize the BPF type system, and finally present HIVE’s isolation mechanism for exclusive types. We close with a security-equivalence analysis against the verifier and a discussion of remaining issues.
Kernel Object Access Pattern
eBPF allows BPF programs to directly read — and in some cases write — selected fields of kernel objects. A common example is the context object: it is passed as the first argument of every BPF program and mirrors a real kernel data structure. For instance, a SOCKET_FILTER program receives a struct sk_buff * as its context — the very same object the kernel uses to track network packets.
Because the kernel object is part of live kernel state, two properties make it fundamentally different from a BPF object:
-
Its address is not known until runtime. Each invocation may receive a different sk_buff instance.
-
Only a small whitelist of fields is accessible, and the legality of each access depends on the program type, the kernel-object type, and the exact field offset.
The verifier enforces these constraints through the full-path analysis: it tracks the type of every pointer, rewrites ldx/stx instructions so that the offsets land on the correct fields of the real kernel structure (the long-standing mechanism introduced by bpf: allow extended BPF programs access skb fields), and rejects any access that falls outside the whitelist. This is exactly the capability HIVE must replicate without relying on full-path analysis.
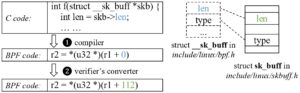
Fig. 1: Kernel objects access pattern in BPF programs.
The context object is the parameter of BPF programs, which mirrors a kernel data structure that is coupled with other kernel data. As shown in Fig. 1, the BPF program accesses the len field of the struct __sk_buff, which is defined in bpf.h. The compiler generates BPF bytecode with the offset as 0, corresponding to the len field in the struct __sk_buff. However, __sk_buff is a virtual structure without any real memory corresponding to. In the kernel, the real structure is struct sk_buff, which is much more complicated. To ensure the right offset, the verifier tracks all memory access instructions to the kernel objects (since the verifier knows the pointers’ type) that require adjustment to the right offset, e.g., 112 for the len field in the sk_buff. This process belongs to the landing check stage in the first blog.
However, such fine-grained kernel object access control is difficult for Hive for two reasons:
-
The LSU instructions cannot access the kernel space, where the kernel objects locate;
-
Hive cannot distinguish which instruction accesses the kernel object.
Simply setting the page where the kernel object is located to be U-Page will be vulnerable to sub-page attacks; Copying all accessible fields of kernel objects into the BPF space each time the BPF program is executed will bring high performance overhead.
This fine-grained, type-driven access control is exactly what makes kernel-object isolation hard for any system that lacks the verifier’s pointer-type information. Prior isolation environments are either prone to sub-page attacks (e.g., mapping the kernel page into a protection domain) or pay heavy per-call copying overhead — or simply leave kernel objects unprotected.
The above challenges are due to the lack of pointer/type tracking capabilities in these works. Without understanding the type of pointers, it is difficult for the isolated execution environment to provide equivalent security guarantees.
To this end, we analyzed the pointer type features of eBPF. In the eBPF subsystem, the security checks are strongly bound to the object types. Under the same security property, pointers to different data types use different security checks. For example, a pointer to the BPF map is checked for out-of-bound access by the pointer’s base and offset (for hashmap, its element), while pointers to the BPF context are checked by a whitelist containing all discrete BPF-accessible offsets.
eBPF Type System: Inclusive vs. Exclusive
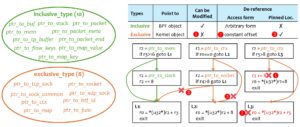
Before designing a solution, it is worth stepping back to look at the BPF pointer type system as a whole. As shown in Fig. 2, BPF pointers fall into two disjoint families:
|
Aspect |
Inclusive types (10) |
Exclusive types (8) |
|
Points to |
BPF object (e.g., map value, stack, packet) |
Kernel object (e.g., sk_buff, sock, ctx) |
|
Address known at load time? |
Yes (static w.r.t. the program) |
No (allocated per invocation) |
|
Pointer arithmetic |
Allowed (with bounds tracking) |
Forbidden |
|
Dereference form |
Arbitrary ptr + reg/imm |
Only ptr + constant_offset |
|
OOB check |
Range check |
Whitelist check |
|
Use site |
Any access instruction |
Pinned: a given instruction may access only one exclusive type |
Fig. 2: Types of pointers in BPF programs and their security checks.
Both families share the same high-level security properties — bounds, type matching, no leakage, no Spectre — but their implementations diverge sharply.
The inclusive type pointers contain 10 types of pointers, e.g., ptr_to_buf, point to BPF data objects that mostly have predictable addresses and sizes at the BPF program loading time (static to the BPF program). For example, the eBPF maps are created before the BPF program is loaded and destroyed after the program is unloaded. Similarly, the BPF stack is always on the top of the kernel stack with a fixed size. In contrast, the exclusive type pointers point to the kernel’s object and do not have a knowable location at the BPF program loading time. For example, the context object of BPF programs with SOCKET_FILTER type is a struct sk_buff object, which is allocated each time the system receives a network packet and passed to the BPF program as its first argument (non-static to the BPF program).
Pointed objects. The inclusive type pointers point to BPF data objects that mostly have predictable addresses and sizes at the load time of the BPF program. For example, the location and the size of BPF map values are determined. In contrast, the exclusive type pointers point to kernel objects and usually do not have a definite address at the load time. For example, the struct sk_buff object will be passed to the BPF program as a context object, and its address may be different every time the BPF program is called.
Generation and propagation. The inclusive type pointers point to BPF data objects, and the exclusive type pointers point to kernel objects. Both types have explicit pointer generation points. E.g., the inclusive type pointers can be generated from relocation items and helper function returns, while the exclusive type pointers have an additional generation point, the program arguments (e.g., the context object). Both types of pointers can be moved across registers, spilled into the BPF stack, and passed to helper functions. However, they cannot be stored in maps or kernel objects.
Pointers’ usage. The difference is that the pointers of the inclusive types are computable and have no restriction on the de-referenced points, while the exclusive type pointers are not computable and can only be de-referenced using the pointer plus a constant offset in one memory access instruction. The constant offset is used to check whether it is accessing the accessible fields (called the whitelist in this blog) of the pointed kernel object in the current program type. Since the allowed offsets of different kernel objects are different, a memory access instruction can only be used to access a specific type of kernel object. The inclusive type pointers do not have the above restrictions. This is why we call them exclusive/inclusive.
Security checks. In the case of checks, most of them have the same properties, but their implementation is different. The out-of-bound check for the inclusive type is a range check, while the whitelist check is used for the other. Both types of pointers are not allowed to leak: (1) To avoid leaking layout information, certain arithmetic operations between pointers are prohibited for the inclusive type pointers, and the computation of the exclusive type pointers is completely prohibited; (2) To avoid leaking locations, both types of pointers are not allowed to be written in maps and kernel objects; (3) To avoid the Spectre attack, the inclusive type pointers are handled by identifying possible Spectre instructions and instrumenting the Spectre patch before them, while the exclusive type pointers are shifted to use arithmetic check and memory access form check. Since the kernel objects are initialized, the exclusive types have no uninitialized read problems. Most of the checks are implemented at the memory access instructions, and some information leakage checks are added at the ALU instructions. The security checks of helper function parameters are the same, which ensures the pointer types match and the memory pointed to does not go out of bounds.
A key observation about the inclusive side is that all 10 inclusive types share the same checking logic and can be merged into a single super-type, mem_type. This unification is what makes Blog 2’s solution work: by compartmentalizing every BPF object into a contiguous BPF space, HIVE replaces ten different range checks with a single space-level check that EL-based hardware isolation can enforce essentially for free.
The exclusive side resists the same trick. Its objects are kernel objects, so they cannot be relocated into the BPF space; and the per-instruction “pinning” semantics requires us to know the type of the pointer being dereferenced — which is exactly what full-path analysis tracks and what HIVE deliberately avoids.
The Exclusive Types Solution
The Initial Idea: PA + LS
Exclusive type pointers exhibit three useful properties:
-
Type-specific — every exclusive pointer carries a definite type that can be identified by serial scanning of the bytecode.
-
Immutable — eBPF forbids any computation on them.
-
Fixed and exclusive use sites — once an instruction is used to access a particular kernel-object type, it can never be used to access any other type.
The first two properties point straight at AArch64’s Pointer Authentication (PA): by signing each exclusive pointer with pacda at its generation site and authenticating it with autda at its use site, HIVE can guarantee pointer integrity without static type tracking. Any tampering corrupts the PAC, autda produces an invalid address, and the next dereference faults — at which point HIVE simply unloads the program.
The third property tells us we can use regular load/store (LS) instructions to reach kernel objects: since each instruction is “pinned” to one type, the access pattern is stable and trustworthy after the first observation.
We call this combination the PA + LS method. It is naturally compatible with the inclusive solution because eBPF disallows conversions between inclusive and exclusive types.
The PA + LS method runs in two stages:
-
Probe. At load time, HIVE scans the bytecode, identifies every exclusive-pointer generation point, and emits a pacda after it. Because the PAC occupies the high 16 bits, the signed value is no longer a valid address; the first dereference therefore traps.
-
Rewrite. HIVE catches the trap, recovers the faulting pointer from the instruction encoding, and tries autda against each of the 8 exclusive types. If none succeed, the pointer was tampered with and the program is unloaded. If one succeeds, HIVE consults the whitelist (using the program type, the matched exclusive type, and the constant offset) to decide whether the access is legal. On success, it patches the original site in place with a regular auth + LS sequence; subsequent executions never trap again.
To make in-place patching possible, HIVE reserves three nop slots in front of every memory-access instruction whose offset is a constant on the whitelist.
This design poses three remaining challenges:
-
C1. How do we design a secure modifier and decide where to sign?
-
C2. How do we ensure the authentication is reliably performed at every use site?
-
C3. How do we close the residual leakage and Spectre gaps left by raw PA?
The next three subsections answer them.
The Design of the Modifier and the Sign Operation (SP-1)
PA is famously vulnerable to pointer substitution attacks: two pointers signed with the same modifier can be swapped without breaking authentication. To prevent (a) substitution across exclusive types, (b) substitution across BPF programs, and (c) replay across historical executions of the same program, the modifier must be unique per type and per execution.
HIVE composes the modifier as
modifier = EXE_CNT | PTR_TYPE
where:
-
EXE_CNT is a 64-bit global execution counter, shared by all BPF programs in the system. It starts from 0 and is advanced by 8 on every BPF invocation, so its lowest 3 bits are always zero and only the upper 61 bits carry information. Being global ensures that the modifier is unique not just across types but across the entire execution history of every program, which prevents replay of signed pointers from earlier invocations — even invocations of other programs.
-
PTR_TYPE is a 3-bit constant identifying one of the 8 exclusive types.
At program entry, HIVE loads EXE_CNT into the reserved register x24 (Fig.3 ❶); two scratch registers x5 and x6 cooperate with pacda/autda. Within an invocation, two pointers of the same type may legally substitute for each other — both pass the same security checks anyway — so we deliberately do not encode any per-pointer freshness.
The pacda instrumentation is placed at four pointer-generation sites:
|
Site |
Instrumentation time |
Where the pacda goes |
|
G1 Relocation entries |
JIT time |
After the relocated load |
|
G2 Helper-function returns |
JIT time |
After the call site |
|
G3 Program entry (e.g., the context) |
JIT time |
In the prologue |
|
G4 Pointers loaded from kernel objects (multi-level) |
Runtime |
After the load, instrumented during probing |
G4 is the only case that cannot be discovered by static scanning. Fortunately, the same exception-based probing mechanism handles it: when a load that produces an exclusive-type pointer first executes, HIVE catches the eventual fault on its dereference, walks back to the producing load, and inserts pacda into one of its reserved nop slots. The kernel objects themselves are never modified.
Authentication and Trust-on-First-Use (SP-1)
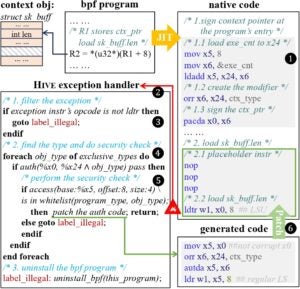
Fig. 3: An example of the exclusive pointer type solution.
The exclusive type pointers can be de-referenced directly and passed into helper functions. For each helper function call, HIVE inserts an autda instruction to authenticate the parameter which is the exclusive type pointer. Once authentication passes, which means the pointer has not been modified and matches the parameter type, it can be safely passed to the helper function.
Every exclusive dereference traps on its first execution, so we can know the use points of the exclusive type pointers lazily by catching and filtering such exceptions (❷❸). It is feasible that the use points of the exclusive type pointers are fixed and exclusive. Once an instruction accesses one type of kernel object, it can no longer access all other types of kernel objects and BPF objects.
Note that since the PAC is stored in the highest 16 bits of the pointer, and the highest 16 bits of the effective addresses in the kernel and BPF spaces are both 1, the sign operation will not change the pointer, that points to the kernel object originally, to point to the BPF space. The signed pointer may point to the user/kernel space or the memory holes, accessing them by using the LSU instructions will trigger the permission fault or the translation fault.
A BPF program usually have different exclusive types of pointers, and HIVE needs to know which type of de-referenced pointer triggers the exception. To this end, HIVE tries to use all types to authenticate the pointer (❹). If no type can pass the authentication, it means that the pointer may be corrupted which leads the BPF program to be uninstalled. If an exclusive type is matched, HIVE will check the whitelist based on the range of access (from the instruction operand), the program type, and the exclusive type (❺). If the check passes, HIVE will generate a regular LS instruction along with the authentication code and patch the original code that triggered the exception (❻). Note that the code cannot corrupt the signed pointer due to it needs to be used to probe subsequent use points.
Analysis on performance and security. It should be noted that every memory access instruction that de-references an exclusive type pointer will trigger an exception and be patched, but it only brings the high performance overhead of probing and patching for the first time, the subsequent security check is completed by the patched code. Empirically, HIVE finishes patching all use sites within the first few invocations of each program.
The security of this scheme rests on trust-on-first-use: as long as the first access through an instruction is legal, every later access through the same instruction must also target the same field — because exclusive pointers are immutable and use sites are pinned. If autda ever fails later (e.g., due to tampering), the resulting invalid address triggers a translation fault and the program is unloaded.
Multi-level Pointers Handling. As mentioned before, three of the four pointer-generation sites (G1–G3) can be discovered by static scanning of the bytecode at JIT time. The fourth, G4 — pointers loaded from inside another kernel object — cannot: the producing instruction is an ordinary ldr whose result type is determined by the offset and the type of the base pointer, information that only full-path analysis would normally track. Inserting pacda at G4 statically would therefore require exactly the analysis HIVE is trying to avoid.
HIVE handles G4 with the same exception-driven probe mechanism used for use sites. When a multi-level exclusive pointer is dereferenced for the first time, the dereference faults (because the pointer was never signed and therefore fails autda). HIVE catches the fault, walks back to the producing ldr, identifies it as a G4 site, and patches one of its reserved nop slots with a pacda. From that point on, every pointer this ldr produces is signed at birth and behaves identically to G1–G3 pointers.
Crucially, this scheme never modifies the kernel object itself — only the BPF code that reads from it. Kernel data structures remain untouched, which is important for both correctness (other kernel code reading the same field sees the real pointer) and deployability (no kernel-side cooperation is required).
The Design of the Type Descriptor Table (SP-2)
Before going further, note that SP-2.2 (use-after-init) is automatically satisfied for exclusive types: every kernel object an eBPF program can reach is allocated and initialized by the kernel itself, never by the BPF program. Uninitialized-read concerns therefore do not apply on the exclusive side, and the rest of this subsection only needs to address the remaining two gaps:
-
SP-2.1 — Pointer confidentiality. Real kernel pointers still sit in BPF-accessible registers, leaking kernel layout.
-
SP-2.3 — Spectre resistance. Current autda implementations are bypassable under speculation, as demonstrated by the PACMAN attack.
Because exclusive pointers cannot be computed on, they behave a lot like opaque handles. This invites a file-descriptor-style redirection: HIVE replaces the real pointer with a small descriptor at its generation site and stores the actual pointer in a per-type descriptor table.
Concretely:
-
For each of the 8 exclusive types, HIVE allocates a table of 65 536 (2¹⁶) entries. Unused slots are filled with invalid addresses.
-
The base address of each table lives in a register reserved from the BPF register allocator.
-
The patched sequence at every use site becomes three instructions:

Fig. 4 The code de-referencing the exclusive type pointers.
For helper calls, HIVE injects the same line 1–2 pair before the call to recover the real pointer for each exclusive-typed argument (saving the original descriptor on the kernel stack), and restores the descriptor on return — so kernel pointers never linger in BPF-accessible registers. The probing protocol is unchanged except that pacda/autda now operate on descriptors rather than raw pointers. The use-site security guarantees match the authentication-based scheme, with two additions: type matching is forced by the choice of table, and any address pulled from the table is by construction either valid or harmless (an invalid filler).
Optimization: Register Promotion. When a descriptor table contains exactly one entry — i.e., at most one live pointer of that type can exist — the lookup is pure overhead. HIVE collapses the entire table into a single reserved register. The canonical example is the context pointer: each invocation has exactly one context.
After register promotion:
-
The context pointer is loaded into reserved register x23 in the program prologue, while its place in the original BPF register is filled with a constant placeholder.
-
Signing of the context pointer is omitted entirely.
-
The patched access sequence collapses from three instructions to one: ldr w1, [x23, #8].
-
For helper calls that take the context, HIVE emits a single mov xn, x23 to materialize the argument.
-
The context-specific descriptor table and its maintenance logic disappear.
Conceptually, register promotion folds the descriptor table and its bookkeeping into the register-reservation logic. Confidentiality and Spectre resistance are preserved because x23 is BPF-inaccessible and the offset has already been validated during probing. For larger tables — e.g., the entries backing a sockmap — HIVE updates the descriptor table on the corresponding lifecycle events (map create/update/delete). This overhead is negligible compared to data-plane accesses.
Putting It All Together: Security Equivalence
The combined inclusive + exclusive design lets HIVE match the verifier’s full-path analysis property by property. Table 1 enumerates all 12 security properties that the verifier’s full-path analysis enforces (as decomposed in Blog 1), together with the HIVE mechanism that subsumes each one. The rows are grouped by the three high-level security goals introduced earlier in this series — SG-1 memory safety (rows 1–4), SG-2 information-flow & speculation safety (rows 5–9), and SG-3 availability (rows 10–12) — so the table can also be read as a checklist for “what HIVE has to do, and where in the design it does it”.
Table 1. Security equivalence analysis between HIVE and the verifier in the full-path analysis.
|
# |
Security property |
How HIVE ensures it |
Equal |
|
1 |
BPF object OOB I/II |
HIVE compartmentalizes all accessible regions of BPF objects into the BPF space, so object-granular OOB is safely relaxed to space-granular OOB. EL-based memory isolation prevents BPF programs from escaping the BPF space. |
✓ |
|
2 |
Kernel object OOB I/II |
Accesses to kernel objects are routed through the descriptor table, which only contains accessible kernel objects. Whether the accessed field of an accessible object is legal is verified during the probe. |
✓ |
|
3 |
Permission violation I |
Compartmentalized map values and packet slabs are mapped into the BPF space with the permitted access rights. |
✓ |
|
4 |
Permission violation II |
The first access to a kernel-object field is captured and checked for the correct access permission during the probe. |
✓ |
|
5 |
Pointer leakage I/II, offset leakage |
The independent BPF space erases all kernel-layout information from inclusive type pointers, making them safe to leak. For exclusive types, the descriptor hides the real pointer and exposes only the use order of kernel objects. |
✓ |
|
6 |
Type mismatch |
HIVE checks pointer-type parameters at helper calls. Inclusive types: a single OR operation forces the pointer into the BPF space; this is safe because all inclusive types are unified under mem_type, which is equivalent to the BPF space. Exclusive types: HIVE forces the helper to retrieve the pointer through the corresponding descriptor table, so type matching is enforced by construction. Scalar casts: nothing needs to be done — pointers no longer carry kernel-layout information, so casting them to scalars is harmless. Note that parameter type matching across BPF-to-BPF function calls is unnecessary in HIVE: the verifier needs it only for intra-procedural state tracking, which HIVE does not perform. |
✓ |
|
7 |
Uninitialized register read |
The verifier rejects reads of uninitialized registers to prevent leakage of residual kernel data. HIVE provides the same guarantee by clearing all BPF-used registers at program entry, and clearing all non-callee-saved registers on every helper return. |
✓ |
|
8 |
Uninitialized stack read I/II |
The BPF stack is decoupled from the kernel stack and zero-initialized at load time. Subsequent invocations may reuse stack content, but only data left by previous executions of the same program — never kernel data. |
✓ |
|
9 |
Spectre V1 filtering, Spectre V1 masking, Spectre V4 |
LSU instructions cannot speculatively access the kernel thanks to the CSV3 patch. The few remaining regular LS instructions HIVE uses are confined to the descriptor tables and the kernel objects they reference, by means of (a) dedicated registers for table base addresses and (b) the descriptor mask, which prevents speculative table OOB. |
✓ |
|
10 |
Kernel stack crash I |
A BPF program could crash the kernel stack by deep nesting of function calls. HIVE places an unmapped guard page at the bottom of the kernel stack so any overflow caused by pushing registers and return addresses is captured by a fault rather than corrupting kernel memory. |
✓ |
|
11 |
Kernel stack crash II |
A BPF program could also crash the kernel stack by allocating a huge frame. Because HIVE separates the BPF stack from the kernel stack, the BPF frame size has no impact on the kernel stack — HIVE’s per-call kernel-stack footprint is fixed. |
✓ |
|
12 |
Timeout / deadlock |
HIVE measures the execution time of each BPF program and uninstalls any program that exceeds the configured budget. |
✓ |
Crucially, HIVE depends on the verifier’s type design — i.e., its interface — but not on its implementation. The complexity and the long history of CVEs that plague full-path analysis are therefore outside HIVE’s TCB.
Discussion
We close this blog with several practical concerns that arose during the design of HIVE. None of them invalidate the equivalence analysis above, but each is important for understanding HIVE’s place in the broader eBPF ecosystem.
Register Use of HIVE. On AArch64, 12 general-purpose registers are unused by the eBPF JIT (%x5–6, %x8, %x13–18, %x23–24, %x28) and are therefore available to HIVE. We reserve them as follows:
-
%x5–6 — scratch registers for pacda/autda.
-
%x13–18 — base pointers for descriptor tables. Although the eBPF type system defines 8 exclusive types in total, a single BPF program type uses at most 6 of them simultaneously (e.g., a SOCKET_FILTER program never needs the descriptor tables for tracing-only types). HIVE allocates descriptor-table base registers on a per-program-type basis, so 6 dedicated registers suffice in practice.
-
%x23 — promoted context pointer.
-
%x24 — EXE_CNT for modifier construction.
%x23 and %x24 are callee-saved, so they survive helper calls without explicit save/restore. %x13–18 are caller-saved and are pushed onto the kernel stack across helper calls.
BPF stack frame size. HIVE cannot know the exact frame size of each BPF function at load time, so it conservatively reserves the eBPF-allowed maximum of 512 B per frame. The BPF stack itself is 8 MB; HIVE eagerly maps only its bottom two pages at load time and demand-allocates the rest on page faults, so the worst-case footprint is paid only by programs that actually need it.
Inter-BPF Isolation. Like user processes, each BPF program in HIVE owns its own BPF space. HIVE switches between them by changing TTBR1_EL1 (i.e., switching the kernel page table). Each BPF program is assigned an ASID and a kernel page table that shares the kernel mappings but has its own (shadow) BPF space. To minimize the cost, HIVE merges BPF programs of the same type and capability set from the same user into a shared BPF space, switching page tables only when execution crosses isolation boundaries.
Additional Helper-Function Handling. The verifier maintains a per-program-type whitelist of allowable helpers, which HIVE reuses unchanged. Of the 209 helpers in Linux 6.6.1, 198 are fully covered by the parameter-sanitization techniques described above. The remaining 11 require special handling because the verifier performs functional checks (not pure security checks) on them. Take bpf_spin_lock(): the verifier statically rejects any second bpf_spin_lock() call that could happen while a lock is already held. Since HIVE no longer performs that intra-procedural state tracking, we rewrite the helper to perform the equivalent record-and-check at runtime.
Security-Property Customization. eBPF programs are loaded with one or more capabilities — CAP_BPF, CAP_NET_ADMIN, CAP_PERFMON, and CAP_SYS_ADMIN — and the verifier already varies the security properties it enforces by capability. For example, programs loaded with only CAP_BPF get the full set, whereas programs with CAP_PERFMON or CAP_SYS_ADMIN are exempt from pointer-leakage and Spectre checks. HIVE can be tuned in the same way: for a privileged capability set, it can fall back from the descriptor-table method to the simpler authentication-based method (or skip Spectre mitigations entirely), trading some property guarantees for performance. The current HIVE prototype enforces the full set by default; we leave this customization to future work.
BPF-Infrastructure Abusing Attacks on HIVE. Our threat model assumes a secure kernel, but it is worth asking what happens if that assumption breaks. The most relevant attacks abuse BPF infrastructure itself:
-
EPF abuses the BPF interpreter and JIT compiler to escalate privileges, by injecting gadgets into the BPF code path. HIVE does not directly defeat EPF, but the two defenses are complementary: EPF protects the kernel from a malicious BPF subsystem, while HIVE protects the kernel from malicious BPF programs. Together they provide bidirectional isolation between BPF and kernel.
-
Spectre V2 / BHI Spectre. A malicious unprivileged BPF program can poison the kernel’s branch predictor and trick the kernel into speculatively leaking memory. HIVE turns most BPF accesses into LSU form, which cannot speculatively read kernel data, but a small number of regular LS instructions are still emitted to access kernel objects through descriptor tables. These can in principle be abused: an attacker could mistrain the predictor so that the table-base register %x23 (Fig. ex_sani) speculatively points to an attacker-chosen address. The mitigation is to rewrite these accesses to use PC-relative addressing, hard-coding the table base into the instruction stream.
Return-to-BPF Attacks. Because the kernel can freely access the shadow BPF space, a kernel-side bug could be turned into a return-to-BPF attack: the kernel dereferences a corrupted pointer that lands in the shadow BPF space, where the attacker has staged a payload. This is structurally identical to the classic return-to-user (ret2usr) attack, with the BPF space playing the role of user space.
The defense is also identical: HIVE reuses Linux’s existing PAN-based ret2usr protection. Since the BPF space is mapped as U-pages, kernel code cannot access it under PAN. Helper functions that legitimately need access either use LSU instructions or temporarily disable PAN around the access — exactly as the kernel already does for legitimate user-space accesses.
Reliance on the Verifier. HIVE depends on the verifier’s pointer-type design — but not on its implementation. This dependency is essential because some BPF features (e.g., the relocation between virtual and real kernel-object layouts, where contiguous fields in the BPF view map onto scattered fields in the real struct sk_buff) need accurate type information to function correctly. Removing the implementation of full-path analysis while retaining the interface of pointer types is the compromise that lets HIVE shrink the verifier without breaking BPF programs.