

This work is supported by the eBPF Foundation Academic Research Grants.
1. Project Overview
With the explosive growth in cloud and ML/AI data centers, energy consumption is now a first-order design constraint. However, existing Linux power management subsystems have not evolved to handle the demands of modern data centers. They face many challenges, such as (1) slow and uncoordinated power management decisions, (2) growing difficulty in meeting workload performance (Quality-of-service) targets, and (3) increasingly volatile data center workloads.
To this end, our project proposes eBPF Governor, an eBPF-based power management framework to deliver highly responsive, low-overhead, QoS-aware dynamic power management. This project enables the creation of custom power management governors in eBPF to control (and coordinate) various processor low-power states, such as frequency states and idle sleep states.
This post serves as the first installment in our series to provide an overview of Linux power management subsystems, their limitations, and how eBPF can modernize the existing power management subsystems. In subsequent blogs, we will discuss how eBPF Governors can be made generalizable, extensible, and coordinated across the various Linux power management subsystems that are normally siloed. We aim to demonstrate that eBPF can modernize the Linux power management subsystems for better power savings and meet the demands of modern data centers.
2. Linux Power Management – An Overview
In Linux, CPU power management is handled by two main components: CPU frequency scaling by the CPUFreq (P-states) subsystem and CPU idle sleep states by the CPUIdle (C-state) subsystem. These subsystems consist of two main components that handle performance scaling and idle state selection: drivers that interface with the hardware and governors that manage the states. The following figure illustrates the existing Linux power management subsystems.
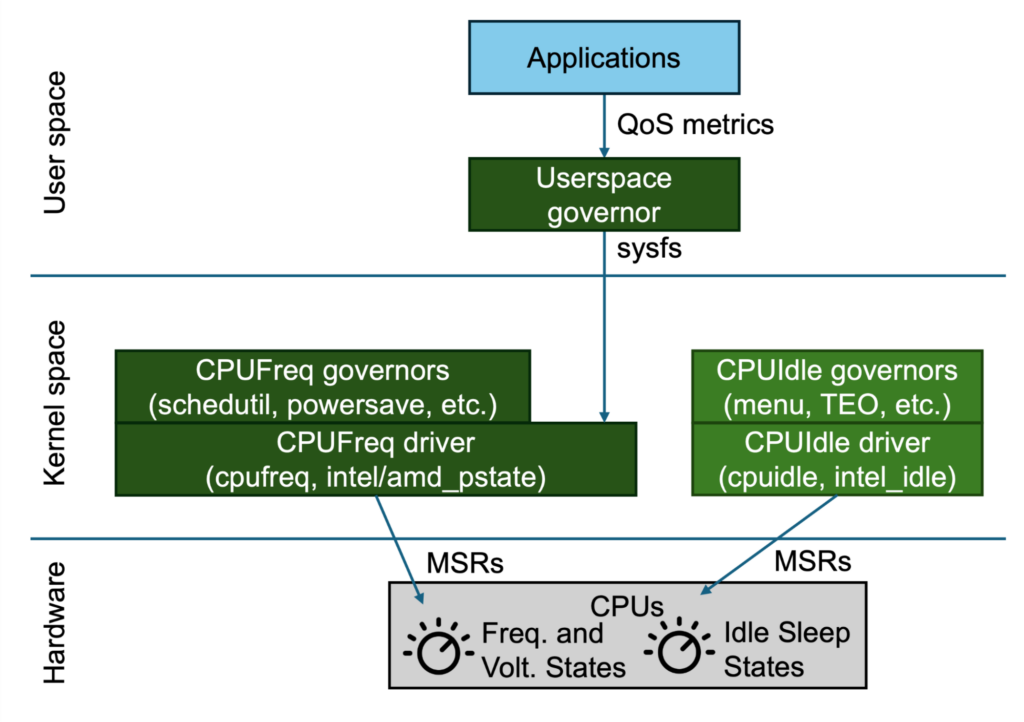
Figure 1. Overview of Linux power management subsystem.
CPU power management is interfaced with the Linux kernel through drivers (e.g. intel_pstate for frequency scaling and intel_idle for idle sleep states), which directly interacts with the processor through model-specific registers (MSRs) to set the hardware’s frequency and voltage states or idle sleep states. For example, we can adjust processor power performance states (P-states) by writing specific frequency values to model-specific registers (MSRs), e.g., setting MSR_IA32_PERF_CTL to 2.4 GHz.
Governors implement algorithms to select the processor’s power performance or idle sleep states. Common governors include the menu governor (which predicts idle duration) for idle sleep state selection, schedutil (which uses CPU utilization data available from the CPU scheduler), ondemand (which uses current CPU load), and powersave (which uses the lowest frequency) for frequency scaling selection. Since these governors reside completely in the driver, they make use of the limited heuristics available in the kernel, such as the Linux scheduler, to make power management decisions.
2.1 QoS-aware Challenges
While these scaling governors can achieve modest power savings, they are not aware of application-level QoS because their only performance feedbacks are kernel-visible load and utilization, which are not necessarily strong indicators of application request latency. For example, the assumption of a linear relationship between CPU load and required frequency does not hold true for all workloads, leading to suboptimal performance or unnecessary energy consumption. Furthermore, many data center workloads are latency-critical and have strict timing requirements. Without direct QoS feedback from applications, scaling governors are not aware of the latency impact of P-state selection decisions.
To enable QoS-aware dynamic power management, existing best practices move the P-state selection algorithms out of kernel space and into userspace through the userspace scaling governor. This allows power management to consider application-specific needs, such as QoS, which kernel-space governors overlook. The userspace governor directly controls processor P-states by writing to a sysfs file, which can lead to high syscall overheads, which can further limit the responsiveness of power management decisions to workload fluctuations, thereby missing crucial opportunities for power savings.
Furthermore, enabling application-level QoS feedback often adds significant complexity to system design. As a result, the entire feedback loop, from capturing application performance to communicating metrics and triggering a power state adjustment, can introduce enough delay to make a timely response impossible, especially for fast-changing or bursty workloads. This motivates the need for new approaches that can provide both fine-grained QoS awareness and minimal overhead with high responsiveness.
2.2 Need for Responsiveness
While in-kernel CPUFreq governors offer better responsiveness than userspace governors, they are not designed to incorporate application feedback efficiently. Thus, there is an essential tradeoff between QoS-awareness and power management responsiveness. This landscape reveals a clear gap: no existing approach provides both the fast, low-overhead control of hardware-based power management solutions and the fine-grained, QoS-aware decision-making required by modern workloads. Bridging this gap calls for a new paradigm in dynamic power management, one that combines rapid response with application-level insight, without introducing additional overhead.
A closer look at the latency of different power management actions highlights the magnitude of this overhead. We observed that setting frequency directly from userspace takes, on average, 31 milliseconds. This number represents only the time to execute the setting operation itself and does not measure the full time until the change in frequency is observed by the hardware. As a result, existing CPUFreq techniques cannot sustain power savings with sub-50ms volatility.
Clearly, userspace-based power managers are fundamentally limited in their ability to respond quickly to changing workload conditions. By comparison, we found that updating frequency from kernel space through eBPF programs is two orders of magnitude faster, requiring only ~200 microseconds.
There is a clear opportunity to leverage the flexibility and low-latency capabilities of eBPF to enable fast, QoS-aware power management in kernel space. Beyond solving the immediate shortcomings of current frameworks, this design also opens up new opportunities for future innovation in power and resource management.
2.3 Extensibility – Looking ahead
Extending for power management coordination: Even if frequency updates can be significantly reduced in legacy systems (i.e. by directly writing to MSRs), the existing Linux power management subsystem remains siloed, each making its own independent power management policies for frequency scaling, idle sleep states, and accelerator (such as GPU) power states. Our prior research findings have identified that short, volatile workloads (from functions/microservices or GPU kernels with short service time) can incur significant frequency state change overhead and that idle periods tend to become fragmented, which prevents idle state entry. Therefore, there exist significant power-saving opportunities when coordinating policies for idle sleep state and GPU states.
Extending beyond CPUs: Currently, the Linux power management subsystem only manages the CPU’s power states. Modern data center servers consist of significant GPU resources, or more generically, accelerator resources, such as TPUs. These accelerators can account for greater than 50% of server power consumption, with CPUs only consuming ~10%. GPU power management is currently handled independently by the hardware and can be guided by system management interfaces (e.g., nvidia-smi) by way of the GPU driver. With the significant rise of non-CPU power, power management of such components should become first-class citizens within the Linux kernel.
3. The Internals of eBPF Power Management
We now present a quick overview of how eBPF Governors can (1) enable custom power management governor policies, (2) provide low-overhead QoS feedback, and (3) interface with power management drivers. To enable custom power management policies, instead of utilizing a userspace governor, we offload custom power management policies into an eBPF program. This enables extensible and customizable policies that we can adapt to different workload requirements and hardware configurations. As of this writing, we have successfully implemented control of frequency states through eBPF and will continue to extend eBPF Governors to target idle sleep states as the project progresses.
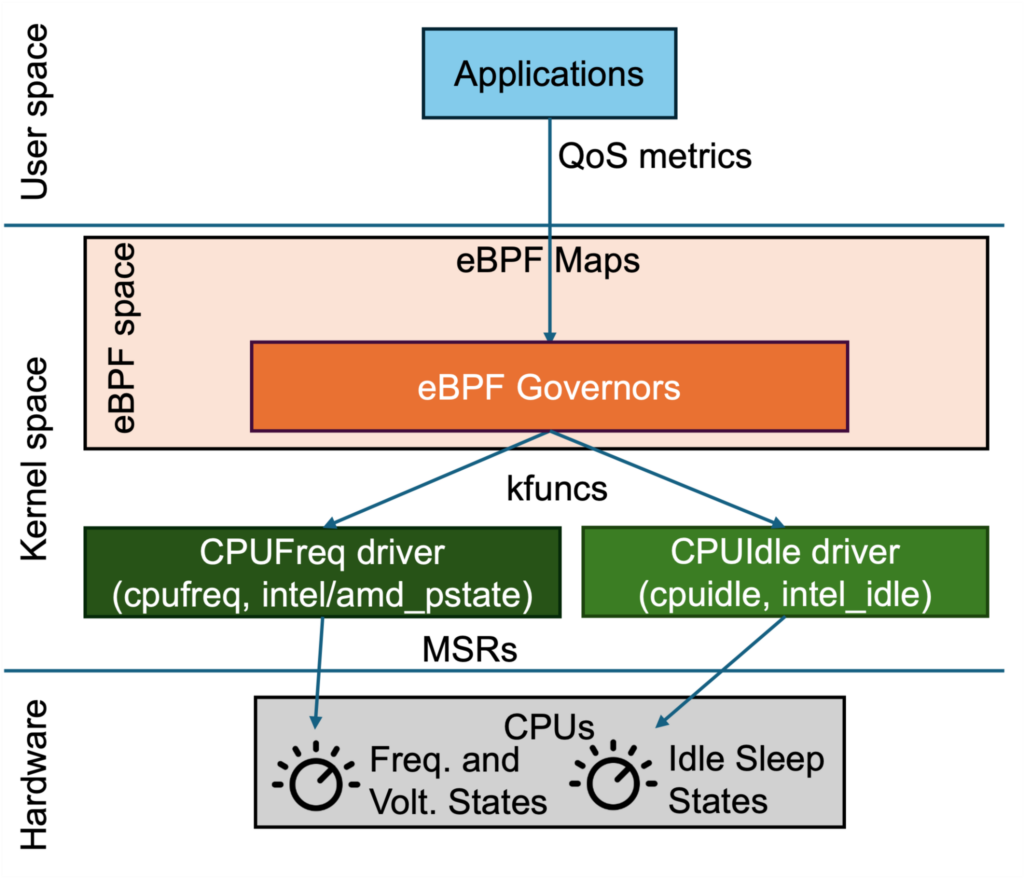 Figure 2: eBPF Governor enables custom eBPF programs to guide processor power management.
Figure 2: eBPF Governor enables custom eBPF programs to guide processor power management.
3.1 eBPF Program Considerations
The eBPF environment lacks support for floating-point arithmetic due to a restricted instruction set. We address this constraint by modifying latency handling and power state selection calculations to avoid floating-point operations. Specifically, we process latencies reported at microsecond granularity, preserving precision without requiring floating-point representation. Power state selection is then calculated using fixed-point arithmetic, where we scale the numerator by a constant (e.g., 1000) and adjust accordingly. This approach ensures precise slack-based decisions without floating-point operations, aligning with eBPF’s computational constraints while maintaining necessary precision.
In multi-core systems, applications may be assigned to multiple CPU cores, each potentially generating concurrent QoS feedback. Because each core independently evaluates QoS and adjusts the performance preference hints for the application’s assigned cores, conflicting decisions may arise. For example, one core might detect a latency violation and boost performance, while another, observing acceptable latency, lowers it to save power. This concurrency introduces race conditions, resulting in inconsistent preference hint settings across the application’s cores, undermining coordinated power management. To ensure safe, coordinated updates to hardware registers across multiple cores, we use the bpf_spin_lock primitive provided by eBPF. This spin lock guarantees that only one core at a time can modify the performance preference hints stored in the model-specific registers, preventing race conditions and inconsistent settings.
3.2 Providing QoS-awareness to eBPF Governor
To provide low-overhead QoS feedback to the eBPF governor, we utilize eBPF’s asynchronous buffers, a shared memory mechanism between user space and kernel space that allows applications to write data directly to a memory region accessible by eBPF programs.
We utilize a BPF ring buffer of type BPF_MAP_TYPE_USER_RINGBUF. This enables applications to write QoS feedback data directly to a memory region accessible by the eBPF program, enabling efficient and low-overhead data exchange. On the eBPF program side, the eBPF program reads the performance metrics from the ring buffer, processes them, and adjusts power states accordingly. This ring buffer lets userspace and eBPF share data asynchronously, providing fast communication for QoS feedback.
3.3 Hooking into Power Management Drivers with kfuncs
Kfuncs are our main mechanism for integrating eBPF Governors with the existing kernel power management drivers. A kfunc is a kernel function that is explicitly marked as callable from eBPF. By marking specific kernel functions as callable from eBPF, we enable eBPF Governors to hook into the same paths that traditional governors use. The eBPF code can then implement QoS-aware policies that respond quickly to changes in workload latency and utilization, without paying the overhead of user space round trips. This makes it possible to react to QoS changes at microsecond time scales, instead of being limited by sysfs polling and context switches.
From the perspective of the hardware, all of this complexity collapses into a few MSR writes. Once the kernel has decided on a target P-state or C-state, it encodes that choice into an MSR and writes it. Because this is the universal endpoint of existing governors, we expose those MSRs through kfuncs. The eBPF Governor computes the desired state and then calls an MSR kfunc to commit it. Specifically, we employ rdmsrl_on_cpu to read current settings from Model Specific Registers (MSRs) and wrmsrl_on_cpu to write updated configurations. These functions facilitate efficient, per-CPU adjustments of HWP preference hints. By restricting access to rdmsrl_on_cpu and wrmsrl_on_cpu via wrappers that expose only necessary functionalities, we ensure safe, controlled operations, avoiding interference with unrelated system components.
3.4 Generalizability challenge
While we have demonstrated the feasibility of power management control from eBPF programs, there still exist many challenges towards generalizing eBPF control for generic power management. First, there exist vendor-specific MSRs and features that deviate between processors. Thus, to effectively manage the power of specific CPUs requires us to dive into the power management driver code to identify the proper MSR register and expected data format that needs to be written to it. Secondly, modern processors exhibit various power management modes (active vs. passive mode) and abstracted performance states that may not necessarily map to specific frequency states. For example, while the processor may run at various frequency levels, only a subset of these frequency levels are exposed to CPUFreq drivers, or abstracted only as bias hints. Thus, existing power management drivers perform extensive mapping of performance states to raw frequency states. When building eBPF Governor policies, we must be cognizant of the mode of operation and performance/frequency states that the processor exposes. If we want to realize the goal of a generalizable and extensible power management governor (à la sched_ext for Linux scheduler), there exist many outstanding challenges that need to be addressed.
4. Summary
The ultimate goal of eBPF Governors is to provide an extensible framework for power management governors across power states (such as frequency states and idle sleep states) and processing units (such as CPUs and GPUs). There are many technical challenges towards demonstrating the feasibility of controlling and coordinating each of these power states and processing units through eBPF facilities. By pushing the boundaries of what eBPF can do with power management, we hope to inspire more use cases of eBPF server resource management in general to make data center servers more efficient.